
SEO们很多都知道这几个关键词:NoIndex,NoFollow,Canonical和Disallow。但是笔者接触下来许多SEO们对这些蜘蛛指引(Search Engine Directives)的理解不足。其实这会造成网站收录和排名的重大影响。本篇,我们就以此作为专题,来介绍各个指引的作用并通过比较来说明它们之间的细微差异。

Link Juice,Link Equity
要理解这些概念,首先我们要对经典的PageRank算法有所了解。出于篇幅的考虑,我们暂且把一个页面所具有的SEO能力叫做大家熟悉的“权重”,这个权重具有流动性,高权重的页面会传递更多权重给它所链接的页面,这个链接不仅是站内链接,还包括我们俗称的外链。另外,页面上的链接越多,每个链接传递出的权重就越低。权重就像知识,传递后传递者不会减少,而被传递者会增多。而我们把所说的传递的权重的量叫做“Link Juice”,或者“Link Equity”。我们且把它翻译成“链接权重”,有时候我们也可以把它看做一种“投票”。
PageRank算法意图,页面权重由总链入权重决定,链出时平分权重
NoIndex:
NoIndex就如它字面的意思,是告知搜索引擎不要索引该页面。用法如下,其他用法见Wikipedia。Google还支持X-Robots-Tag HTTP header中的NoIndex信息用来支持pdf这种非HTML文档。
<meta name=”robots” content=”noindex“>
被设为NoIndex的页面无法获得页面权重。但是并不是说这个页面所链出的页面就无法获得链接权重。只要该页面未被设为NoFollow,其一样具有“临时权重值”,而这个值会流出到它所链出的页面。
NoIndex虽被Google,Yahoo等主流搜索引擎所使用,但百度尚不支持该标签。因此我们若不想页面被百度索引,还需要使用robots.txt。
NoFollow:
NoFollow的意思就是请搜索引擎蜘蛛留步。有两种用法,其一是和上面NoIndex一样,表示“不要再继续抓取这个页面链出的任何链接”:
<meta name=”robots” content=”nofollow“>
另一种是指定不要抓取某个特定链接:
<a href=”http://www.seopz.com/” rel=”nofollow”>Link text</a>
要查看NoFollow,你可以通过极诣介绍过的那几个实用的SEO插件来实现。
NoFollow阻止了链接权重向目标页面流动,被NoFollow的页面将无法获得链接权重。如果如上述第二种方法部署就相当于减少了权重流出的目的地数,从而每个目标页面获得的链接权重会相应增加。在经典的技术SEO中,通过应用NoFollow可以很好地防止“权重分散”,更重要的是它可以有效利用搜索引擎的Crawl Budget,即抓取配额。
我们注意到,搜索引擎并不是每次抓取网站时都把网站遍历一遍的。你可以通过分析网站服务器的访问记录了解搜索引擎的爬虫行为。为了防止蜘蛛漫无目的地爬行,你需要使用NoFollow来指引蜘蛛在有限的爬行页面数配额内抓到你的“重点内容”,起码是你认为的高质量内容。如果蜘蛛的抓取配额大量浪费在垃圾页面上,那么优质页面的收录就会造成问题。
百度支持NoFollow标签的上述两种用法。
Canonical:
Canonical标签用于声明页面的唯一原型页面。它通知搜索引擎当前页面是Canonical页面的一个变种,当考虑收录时需忽略变种而收录原型页面。用法如下:
<link rel=”canonical” href=”http://www.seopz.com/” />
Canonical并不阻止搜索引擎蜘蛛的爬行,而仅仅对收录做出指引,它可以有效避免重复内容带来的负面影响。Canonical的另一个优点是变种页面获得的链接权重会被带回它的原型页面。同时变种页面流出的链接权重依然有效。尽管有这些优点,Canonical并不能节省抓取配额,因此当搜索引擎需要爬行大量变种页面时索引效率会下降。
百度支持Canonical标签。但仅限于桌面和移动版本之间的适配和MIP页面。
Disallow:
Disallow是在robots.txt中对搜索引擎爬虫的指引参数。它表示“请不要抓取这些页面”。请注意它并不表示“请删除这些被索引的页面”。尽管某些页面被设为Disallow,搜索引擎仍然可能索引这样的页面(注:下图中百度蜘蛛的大小写不敏感,因此不必重复一遍。):

百度无视优衣库屏蔽索引强行索引展示结果(也有可能为Disallow之前被索引)
尽管搜索引擎(不仅仅是百度,谷歌一样会)可能不遵守robots.txt,robots.txt的Disallow依然是节省抓取配额并阻止百度这样不遵守NoIndex指引的搜索引擎索引特定页面的有效方式。Disallow的缺点同样很明显,首先被Disallow的页面无法被爬行和索引因此无法贡献链接权重给其链出的页面,其自身的权重也无从谈起。另一个缺点是它会浪费指向它的来自其他网站的外链带来的宝贵的链接权重。
NoIndex + NoFollow:
理解了NoIndex和NoFollow的意义,两者同时应用的作用就不难理解了。这里要再次提醒下,百度并不支持NoIndex标签。NoIndex,NoFollow同时应用无法给该页面带来页面权重,因为该页面不会被索引。同时也没有任何链接权重可以流向被链接到的页面。如果外链指向该页面将会造成链接权重的损失,搜索引擎还是会对该页面进行爬行从而无法节省抓取配额。
由此我们看出NoIndex + NoFollow与Disallow相比没有任何优势,只是在页面管理方面比动态robots.txt更灵活。如果该页面只是一个变体,我们推荐使用Canonical,这样虽然还会消耗抓取配额,但是页面权重和链接权重得以保留。
NoIndex,Follow
同单独使用NoIndex,不赘述。
总结一下
我们把上述内容总结一下,见下图:
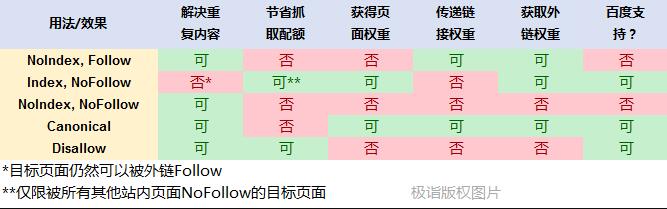
这样一来,通过比较我们就可以对各种应用的细微差别有更清晰的认识。
来源:seo篇章 https://www.seopz.com/seo/3968.html
